“.群体视频编码”的版本间的差异
| (未显示1个用户的10个中间版本) | |||
| 第1行: | 第1行: | ||
| + | 作者姓名:王瀚漓 职称:教授 单位:同济大学 电话:021-69585002 电子邮件:hanliwang@tongji.edu.cn | ||
| + | |||
| + | ---- | ||
'''群体视频编码 group video coding''' 目前,也可以称为近似视频编码(Near-Duplicate Video Coding),其目的是对近似视频数据进行群体联合压缩,尽可能减少近似视频数据中的冗余信息,用更少的数据表征视频,以便传输和存储。随着社交网络和多媒体技术的发展、手持拍照设备的普及,在线视频数据以惊人的速度增长,这些视频被下载、观看、编辑、重新上传到网上,因此互联网上充斥着大量的近似视频[1],近似视频编码技术应运而生。而在近似视频编码之前,需要检测出哪些视频属于近似视频。因此,近似视频编码通常包括检测和编码两个部分。 | '''群体视频编码 group video coding''' 目前,也可以称为近似视频编码(Near-Duplicate Video Coding),其目的是对近似视频数据进行群体联合压缩,尽可能减少近似视频数据中的冗余信息,用更少的数据表征视频,以便传输和存储。随着社交网络和多媒体技术的发展、手持拍照设备的普及,在线视频数据以惊人的速度增长,这些视频被下载、观看、编辑、重新上传到网上,因此互联网上充斥着大量的近似视频[1],近似视频编码技术应运而生。而在近似视频编码之前,需要检测出哪些视频属于近似视频。因此,近似视频编码通常包括检测和编码两个部分。 | ||
| 第5行: | 第8行: | ||
'''编码''' 目前,近似视频都是通过特定的视频编码标准(如H.264/AVC[7])单独编码,导致近似视频间的冗余信息没有得到有效地去除。为了提高近似视频的压缩效率,近似视频编码可以借鉴多视点视频编码框架(图1)。多视点视频指的是由不同视点的多个摄像机从不同视角拍摄同一场景得到的一组视频信号,因此视频内容具有极强的视点间相关性[8]。多视点视频编码技术利用图2(以2个视点为例,可以拓展到多个视点)所示的编码预测结构,在视点内预测的基础上,加入了视点间的预测技术,提高多视点视频的压缩效率。而检测得到的近似视频之间具有一定的相似度,每一个视频可以当作多视点视频系统中的一个视点,采用图2所示的多视点联合编码预测结构,去除近似视频间的冗余信息。目前有两种基于图2的近似视频编码框架,在提高近似视频压缩效率方面取得了一定的效果。 | '''编码''' 目前,近似视频都是通过特定的视频编码标准(如H.264/AVC[7])单独编码,导致近似视频间的冗余信息没有得到有效地去除。为了提高近似视频的压缩效率,近似视频编码可以借鉴多视点视频编码框架(图1)。多视点视频指的是由不同视点的多个摄像机从不同视角拍摄同一场景得到的一组视频信号,因此视频内容具有极强的视点间相关性[8]。多视点视频编码技术利用图2(以2个视点为例,可以拓展到多个视点)所示的编码预测结构,在视点内预测的基础上,加入了视点间的预测技术,提高多视点视频的压缩效率。而检测得到的近似视频之间具有一定的相似度,每一个视频可以当作多视点视频系统中的一个视点,采用图2所示的多视点联合编码预测结构,去除近似视频间的冗余信息。目前有两种基于图2的近似视频编码框架,在提高近似视频压缩效率方面取得了一定的效果。 | ||
| − | + | [[文件:Crowd_Vedio_Code_1_a.png|550px]] [[文件:Crowd_Vedio_Code_1_b.png|300px]] | |
| − | |||
| − | |||
| − | + | <div style="text-align: center;">图1 多视点视频和近似视频编码框架(左:多视点视频编码框架 右:近似视频编码框架)</div> | |
框架1[9] 在图2的基础上,加入了视频分析技术。以两个视频为例,在编码之前,利用近似视频检测技术[10]判断两个视频是否为近似视频,如果满足近似视频的条件,选取其中的一个作为图2中的视点V0,另外一个作为视点V1。此外,在图2中,视点V1的当前编码帧只能参考视点V0内对应位置帧,而根据近似视频的特性,这种视点间参考帧选取策略往往并不是最优的。因此,视频分析技术的另一个作用是从视点V0内找出一个和视点V1中当前编码帧相似度最高的图像,作为最优的视点间参考帧。 | 框架1[9] 在图2的基础上,加入了视频分析技术。以两个视频为例,在编码之前,利用近似视频检测技术[10]判断两个视频是否为近似视频,如果满足近似视频的条件,选取其中的一个作为图2中的视点V0,另外一个作为视点V1。此外,在图2中,视点V1的当前编码帧只能参考视点V0内对应位置帧,而根据近似视频的特性,这种视点间参考帧选取策略往往并不是最优的。因此,视频分析技术的另一个作用是从视点V0内找出一个和视点V1中当前编码帧相似度最高的图像,作为最优的视点间参考帧。 | ||
[[文件:Crowd_Vedio_Code_2.png|800px|center]] | [[文件:Crowd_Vedio_Code_2.png|800px|center]] | ||
| − | + | ||
| − | + | <div style="text-align: center;">图2 多视点视频编码预测结构示例</div> | |
框架2[11]在框架1的基础上增加了亮度调节和仿射变换预处理模块,进一步提高视点间的预测效率。下面,介绍一下框架2中的亮度调节器和仿射变换预处理模块。 | 框架2[11]在框架1的基础上增加了亮度调节和仿射变换预处理模块,进一步提高视点间的预测效率。下面,介绍一下框架2中的亮度调节器和仿射变换预处理模块。 | ||
| 第21行: | 第22行: | ||
'''亮度调节''' 假设视点V1中当前编码帧为Id,其在视点V0内的最优参考帧为Ib,亮度调节器的作用是减少Id和Ib之间的全局亮度差异。首先计算Id和Ib的颜色直方图并且以像素点数目的降序排列,表示为: | '''亮度调节''' 假设视点V1中当前编码帧为Id,其在视点V0内的最优参考帧为Ib,亮度调节器的作用是减少Id和Ib之间的全局亮度差异。首先计算Id和Ib的颜色直方图并且以像素点数目的降序排列,表示为: | ||
| − | [[文件:Crowd_Vedio_Code_3.png| | + | [[文件:Crowd_Vedio_Code_3.png|500px|center]]<div style="text-align: right;">(1)</div> |
其中,H(x)指经过重排的颜色直方图,x代表Id或Ib,n代表直方图条目,对于8位图像,n的值为256。亮度调节器的目的是求解一个亮度转换方程g(﹒),使得下列直方图差异最小化: | 其中,H(x)指经过重排的颜色直方图,x代表Id或Ib,n代表直方图条目,对于8位图像,n的值为256。亮度调节器的目的是求解一个亮度转换方程g(﹒),使得下列直方图差异最小化: | ||
| − | [[文件:Crowd_Vedio_Code_4.png| | + | [[文件:Crowd_Vedio_Code_4.png|300px|center]]<div style="text-align: right;">(2)</div> |
为了简化计算,可以将g(﹒)设为一阶线性方程: | 为了简化计算,可以将g(﹒)设为一阶线性方程: | ||
| − | [[文件:Crowd_Vedio_Code_5.png|200px]] | + | [[文件:Crowd_Vedio_Code_5.png|200px|center]]<div style="text-align: right;">(3)</div> |
其中,''a''和''b''为标量系数,可以通过线性回归计算得到。在实际计算中,往往大多数的像素值分布在前四个条目中。 | 其中,''a''和''b''为标量系数,可以通过线性回归计算得到。在实际计算中,往往大多数的像素值分布在前四个条目中。 | ||
2017年1月20日 (五) 03:59的最新版本
作者姓名:王瀚漓 职称:教授 单位:同济大学 电话:021-69585002 电子邮件:hanliwang@tongji.edu.cn
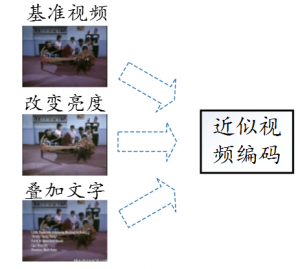
群体视频编码 group video coding 目前,也可以称为近似视频编码(Near-Duplicate Video Coding),其目的是对近似视频数据进行群体联合压缩,尽可能减少近似视频数据中的冗余信息,用更少的数据表征视频,以便传输和存储。随着社交网络和多媒体技术的发展、手持拍照设备的普及,在线视频数据以惊人的速度增长,这些视频被下载、观看、编辑、重新上传到网上,因此互联网上充斥着大量的近似视频[1],近似视频编码技术应运而生。而在近似视频编码之前,需要检测出哪些视频属于近似视频。因此,近似视频编码通常包括检测和编码两个部分。
检测 近似视频指内容几乎一样的视频(或视频片段),但是在文件格式、编码参数、光度变化(颜色以及光照变化)、编辑方式(插入水印、边框等)、长度或者某些特定变化下(帧的增加和删除等)有所不同[2]。关于近似视频检测方法的研究已日渐成熟,根据检测特征可分为两类:全局特征检测方法和局部特征检测方法。全局特征检测方法更快速,主要考虑关键帧的颜色[3]、时序[4]等特征信息;局部特征检测方法准确度更高,主要通过提取关键帧的局部特征,例如:尺度不变特征变换(Scale Invariant Feature Transform, SIFT)[5]、PCA-SIFT[6]等特征信息,检测近似视频。
编码 目前,近似视频都是通过特定的视频编码标准(如H.264/AVC[7])单独编码,导致近似视频间的冗余信息没有得到有效地去除。为了提高近似视频的压缩效率,近似视频编码可以借鉴多视点视频编码框架(图1)。多视点视频指的是由不同视点的多个摄像机从不同视角拍摄同一场景得到的一组视频信号,因此视频内容具有极强的视点间相关性[8]。多视点视频编码技术利用图2(以2个视点为例,可以拓展到多个视点)所示的编码预测结构,在视点内预测的基础上,加入了视点间的预测技术,提高多视点视频的压缩效率。而检测得到的近似视频之间具有一定的相似度,每一个视频可以当作多视点视频系统中的一个视点,采用图2所示的多视点联合编码预测结构,去除近似视频间的冗余信息。目前有两种基于图2的近似视频编码框架,在提高近似视频压缩效率方面取得了一定的效果。
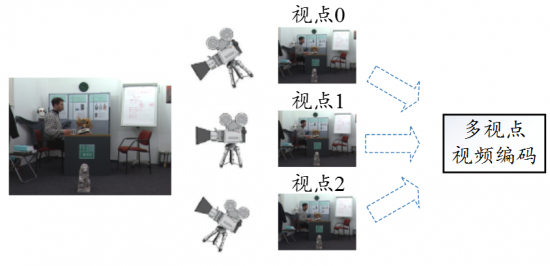


框架1[9] 在图2的基础上,加入了视频分析技术。以两个视频为例,在编码之前,利用近似视频检测技术[10]判断两个视频是否为近似视频,如果满足近似视频的条件,选取其中的一个作为图2中的视点V0,另外一个作为视点V1。此外,在图2中,视点V1的当前编码帧只能参考视点V0内对应位置帧,而根据近似视频的特性,这种视点间参考帧选取策略往往并不是最优的。因此,视频分析技术的另一个作用是从视点V0内找出一个和视点V1中当前编码帧相似度最高的图像,作为最优的视点间参考帧。

框架2[11]在框架1的基础上增加了亮度调节和仿射变换预处理模块,进一步提高视点间的预测效率。下面,介绍一下框架2中的亮度调节器和仿射变换预处理模块。
亮度调节 假设视点V1中当前编码帧为Id,其在视点V0内的最优参考帧为Ib,亮度调节器的作用是减少Id和Ib之间的全局亮度差异。首先计算Id和Ib的颜色直方图并且以像素点数目的降序排列,表示为:

其中,H(x)指经过重排的颜色直方图,x代表Id或Ib,n代表直方图条目,对于8位图像,n的值为256。亮度调节器的目的是求解一个亮度转换方程g(﹒),使得下列直方图差异最小化:

为了简化计算,可以将g(﹒)设为一阶线性方程:

其中,a和b为标量系数,可以通过线性回归计算得到。在实际计算中,往往大多数的像素值分布在前四个条目中。
仿射变换 假设Ib是Ib经过亮度调节处理后的图像,仿射变换的作用是求解一个单应矩阵M,使得Ib和Id之间的几何位置差异最小。为了能够得到更准确的单应矩阵M,首先用SURF[12]算子快速提取Ib和Ib的局部特征;然后,利用FLANN[13]算法快速匹配提取到的局部特征;最后,根据匹配的特征对,利用RANSAC[14]算法求解单应矩阵M。Id的最优视点间参考帧可以由M(Ib)生成。
发展趋势 随着多媒体技术的发展,在线视频爆炸性地增长,近似视频编码技术尤为重要。目前的近似视频编码框架在一定程度上提高了压缩效率,但还有很大的提高空间。更符合视频编码特性的近似视频检测技术和最优的视频分组技术是未来的发展趋势。同时,由于现有的近似视频编码框架采用多视点视频编码框架,导致复杂度成倍的增长,因此,利用GPU和并行技术提高近似视频的编码速度也是非常值得研究的方向。
参考文献
[1] X. Wu, A. G. Hauptmann, and C.-W. Ngo, “Practical elimination of near-duplicates from web video search,” Proc. ACM MM’07, Sept. 2007, pp. 218-227.
[2] M. Cherubini, R. de Oliveira, and N. Oliver, “Understanding near-duplicate videos: a user-centric approach,” Proc. ACM MM’09, Oct. 2009, pp. 35-44.
[3] E. Kasutani and A. Yamda, “The MPEG-7 color layout descriptor: a compact image feature description for high-speed image/video segment retrieval,” Proc. ICIP’01, Oct. 2001, pp. 674-677.
[4] C. Kim and B. Vasudev, “Spatiotemporal sequence matching for efficient video copy detection,” IEEE Trans. Circuits Syst. Video Technol., vol.15, no.1, pp. 127-132, Jan. 2005.
[5] D. Lowe, “Distinctive image features from scale-invariant keypoints”, Int. J. Computer Vision, vol. 60, no. 2, pp. 91-110, Nov. 2004.
[6] Yan K. and R. Sukthankar, “PCA-SIFT: a more distinctive representation for local image descriptors”, Proc. CVPR’04, Jun. 2004, PP. 506-513.
[7] T. Wiegand, G. J. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H.264/AVC video coding standard,” IEEE Trans. Circuits Syst. Video Technol., vol. 13, no. 7, pp. 560-576, Jul. 2003.
[8] P. Merkle, A. Smolic, K. Muller, and T. Wiegand, “Efficient prediction structures for multiview video coding,’’ IEEE Trans. Circuits Syst. Video Technol., vol. 17, no. 11, pp. 1461-1473, Nov. 2007.
[9] H. Wang, M. Ma, Y.-G. Jiang, and Z. Wei, “A framework of video coding for compressing near-duplicate videos,” Proc. MMM’14, Jan. 2014, pp. 518-528.
[10] H. Jegou, M. Douze, and C. Schmid, “Improving bag-of-features for large scale image search,” Int. J. Computer Vision, vol. 87, no. 3, pp. 316–336, May 2010.
[11] H. Wang, M. Ma, and T. Tian, “Effectively compressing near-duplicate videos in a joint way,” Proc. ICME’15, Jun. 2015, pp. 1-6.
[12] H. Bay, T. Tuytelaars, and L. V. Gool, “SURF: speeded up robust features,” Proc. ECCV’06, May 2006, pp. 404–417.
[13] M. Muja and D. Lowe, “Scalable nearest neighbor algorithms for high dimensional data,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 11, pp. 2227–2240, Nov. 2014.
[14] M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,’’ Comm. of the ACM, vol. 24, no. 6, pp. 381-395, Jun. 1981.